您现在的位置是: 网站首页> 学习笔记> JS逆向 JS逆向
猿人学-第一届Web端爬虫攻防大赛第三题
2021-01-25 [JS逆向] [猿人学刷题] 8211人已围观
刷题地址:http://match.yuanrenxue.com/match/3
这题看起来简单,但是有个坑卡了好久;
多点几次请求,不难发现每次请求数据之前都会先去请求一个logo的链接;
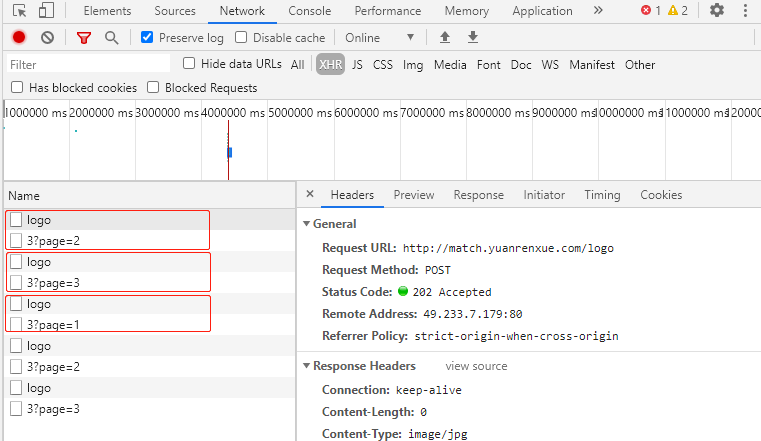
如果我们不请求这个logo链接,直接去请求数据页面,会响应一堆js代码,
分析一下,也分析不出个啥来;
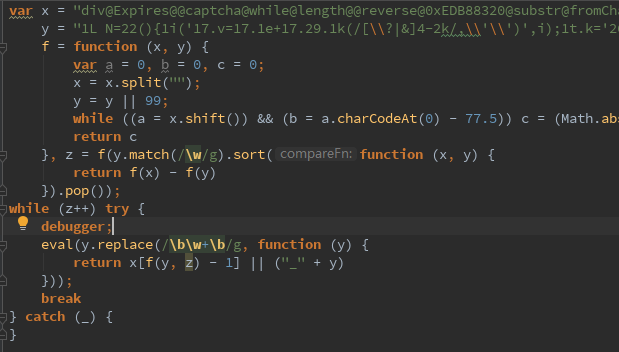
模拟浏览器流程,保持会话状态,用session请求两次(先请求logo页面,再请求数据页面);
发现还是取不到正确数据,从浏览器里拷headers、改headers(一个一个的删除,一个一个的加),
另外debug时发现,请求logo页面并没有Set-Cookie,而浏览器里却是有Set-Cookier的,卡住了,
方法试遍了都还是不行,最后没办法只有试着打开fiddler抓包看看有没有啥没抓到的;
发现fiddler抓包与浏览器抓包结果也是一样的,唯一不同的是fiddler里的headers好像与浏览器有些不同;
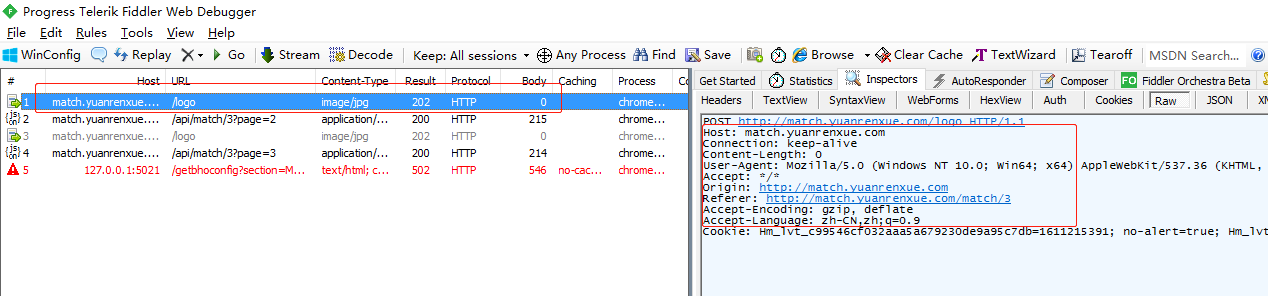
把fiddler里的headers拷出来请求数据,发现OK了。真的是坑。。 然后又试着把这能请求到数据的headers改来改去,发现改了以后也不能取到数据, 貌似大多请求头都是需要的,而且还有顺序要求。
总结一下,以后直接去fiddler里拷headers好了,免得遇到这种坑卡半天。
python代码
import requests
import json
url1 = 'http://match.yuanrenxue.com/logo'
url2 = 'http://match.yuanrenxue.com/api/match/3?page={}'
headers = {
'Host': 'match.yuanrenxue.com',
'Connection': 'keep-alive',
# 'Content-Length': '0',
'User-Agent': 'yuanrenxue.project',
'Accept': '*/*',
'Origin': 'http://match.yuanrenxue.com',
'Referer': 'http://match.yuanrenxue.com/match/3',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
if __name__ == '__main__':
sess = requests.session()
sess.headers = headers
values = []
for page in range(1, 6):
sess.post(url1)
res = sess.get(url2.format(page))
values.extend([val['value'] for val in json.loads(res.text)['data']])
print(res.text)
print(values)
print(max(values, key=values.count)) # 取list中出现频率最高的值
下一篇:国家税务总局A级纳税人采集爬虫
文章评论
#2025-12-06 20:47 @ Josephbooge:
信息丰富的 关于旅行的门户! 读起来很愉快! <a href=https://iqvel.com/zh-Hans/a/%E8%A5%BF%E7%8F%AD%E7%89%99/%E5%B7%B4%E7%89%B9%E6%B4%9B%E4%B9%8B%E5%AE%B6>格拉西亞大道</a> 确实少有, 如此积极的氛围。点赞。
#2025-12-16 00:48 @ Josephbooge:
很棒的 旅行文章! 做得真好。 <a href=https://iqvel.com/zh-Hans/a/%E6%96%B0%E5%8A%A0%E5%9D%A1/%E8%A5%BF%E7%BD%97%E7%B4%A2%E5%A0%A1>城市度假</a> 我早就想, 参观你们描述的目的地。很开心。
#2026-01-06 16:38 @ Josephhit:
研究你的文章, 我感受到, 旅行带来灵感。无限感谢 能量。 <a href=https://iqvel.com/zh-Hans/a/%E9%98%BF%E8%81%94%E9%85%8B/%E8%BF%AA%E6%8B%9C%E5%96%B7%E6%B3%89>观景平台</a> 你们的项目 确实 打开世界。不要放弃!
#2026-02-03 07:02 @ Josephbooge:
所有文章都令人印象深刻。由衷感谢 温暖。 <a href=https://iqvel.com/zh-Hans/a/%E4%BF%84%E7%BD%97%E6%96%AF/%E8%8D%AF%E5%89%82%E5%9B%AD>城市綠地</a> 照片令人惊艳。继续保持 独创性。
添加评论
点击排行
本栏推荐
标签云
热评文章
- django使用qq邮箱发送邮件
- mysql8设置数据库远程连接
- pip修改下载源为国内源
- win10看不到win7共享的文件夹的解决方法
- SQLyog连接 Mysql 8.0.11 报error no.1251- Client does not support authentic...
- 使用Oracel Net Nanager配置Oracle数据库远程访问
- 将anaconda的下载源切换为国内的源
- Python+selenium+firefox设置代理IP
- selenium+firefox+js实现动态设置firefox浏览器代理IP
- scrapy文件下载(高新技术企业认定网)
- Python调用JS代码
- Chrome浏览器的overrides的使用
站点信息
- 建站时间:2021-01-01
- 网站程序:Django 3.1.2
- 文章统计:54篇
- 文章评论:72条
- 统计数据:
#2025-12-01 03:17 @ Josephbooge:
精彩的 旅游网站! 不要停下! <a href=https://iqvel.com/zh-Hans/country/%E6%84%8F%E5%A4%A7%E5%88%A9>簽證花費</a> 极好的 旅游网站, 保持 继续下去。致敬!