您现在的位置是: 网站首页> 学习笔记> 爬虫 爬虫
国家税务总局A级纳税人采集爬虫
2021-01-30 [JS逆向] 6497人已围观
网址:http://hd.chinatax.gov.cn/nszx/InitCredit.html 主要是学习为主,没有做大量爬取,大量爬取应该得上代理池。 用无痕模式多刷新几次,可以发现主要是cookie中的C3VK值在变, 用fiddler抓包,第一次请求返回了一堆JS代码:
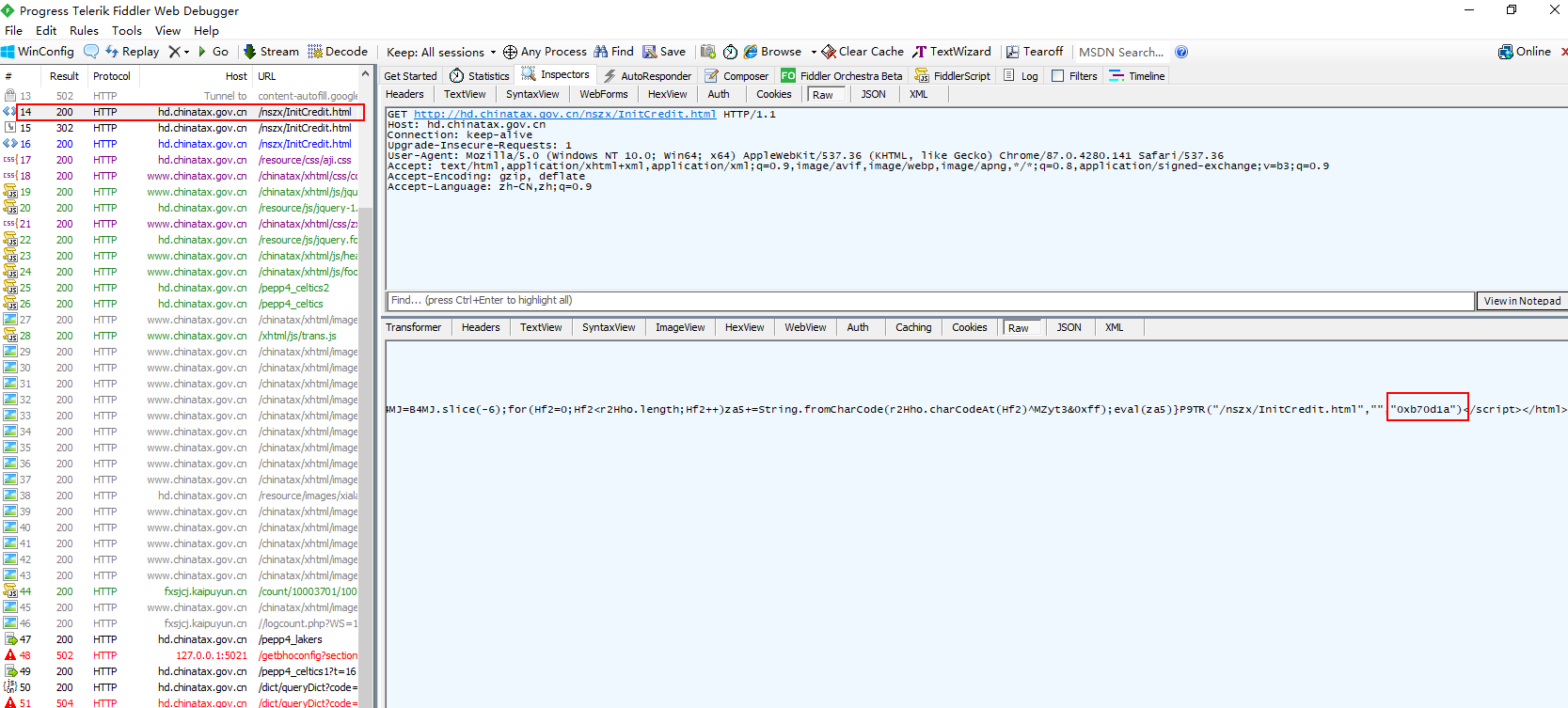
拷出来格式化看一下:
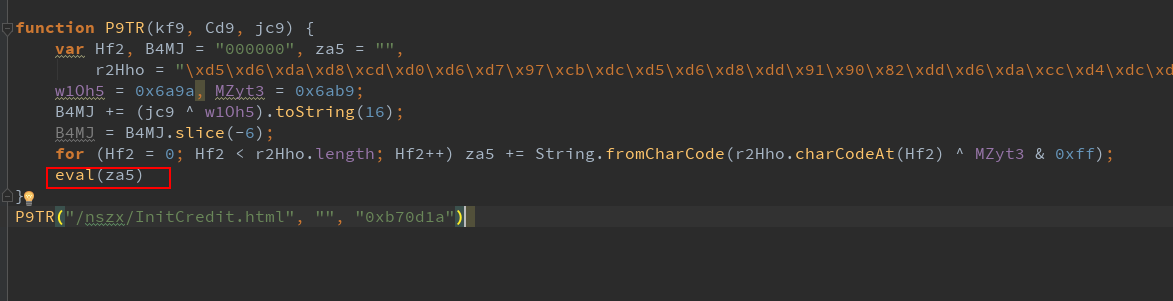
代码比较简单稍微改一下放浏览器看一下eval中的代码是什么:
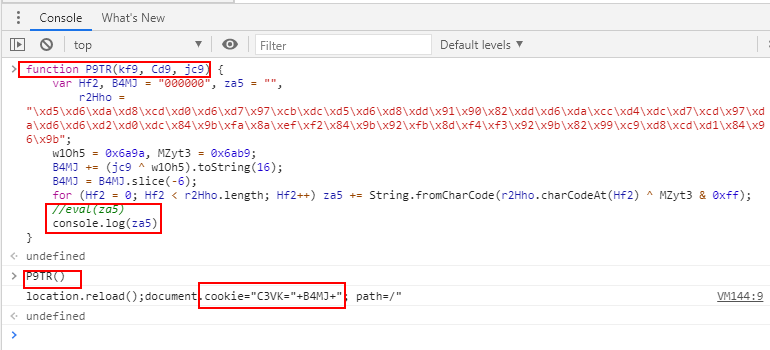
可以看出这里设置了cookie中的C3VK,且C3VK的值等于B4MJ(这个动态的,每次都不一样), 把多余的代码删掉:
function P9TR(jc9) {
var B4MJ = "000000";
w1Oh5 = 0x6a9a, MZyt3 = 0x6ab9;
B4MJ += (jc9 ^ w1Oh5).toString(16);
B4MJ = B4MJ.slice(-6);
return B4MJ;
}
P9TR("0xb70d1a");
然后就是试着模拟一下请求过程:
import requests
import cchardet
import re
import execjs
import json
class Chinatax(object):
def __init__(self):
# 第一次请求的页面
self.url_first = "http://hd.chinatax.gov.cn/nszx/InitCredit.html"
# 数据请求页面地址
self.url_data = "http://hd.chinatax.gov.cn/service/findCredit.do"
# 第一次请求的headers
self.headers_first = {
'Host': 'hd.chinatax.gov.cn',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
# 数据请求页面的headers
self.headers_data = {
'Host': 'hd.chinatax.gov.cn',
'Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Referer': 'http://hd.chinatax.gov.cn/nszx/InitCredit.html',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
self.cookies = {
'yfx_c_g_u_id_10003701': 'ck21013011582214923037283811800',
'yfx_f_l_v_t_10003701': 'f_t_1611979102489__r_t_1611979102489__v_t_1611979102489__r_c_0',
'JSESSIONID': '52B2AD0DC6E943B7BFD1E25A5E6B9907',
'_Jo0OQK': '595C840C56C2736D27D1688C38C71781A0257625D274062322959B6DD768A3F621B6327A4A63E8038C69151C3B0C3FD7925A2F5E8639C032F51AC15E028DC9C2A671B918CCA8FE3BB9470EE0D297309F84070EE0D297309F8403E79D27820DC97D0B5F5E5E09BAC0B2AGJ1Z1Vw==',
}
self.payload = {
'page': '100',
'location=': '110000',
'code': '',
'name': '',
'evalyear': '2019',
'cPage': ''
}
self.session = requests.session()
self.session.headers.clear()
self.session.headers.update(self.headers_first)
self.session.cookies.update(self.cookies)
def get_cookie_c3vk(self, response):
# 生成C3VK
args1 = ''
c3vk = ''
try:
args1 = re.search(r',"(\w.*?)"\)</script', response.text).group(1)
print('args1: ', args1)
except:
c3vk = re.search('cookie="C3VK=(\w.*?);', response.text).group(1)
if args1:
js_text = '''
function get_c3vk(jc9) {
var B4MJ = "000000";
w1Oh5 = 0x6a9a, MZyt3 = 0x6ab9;
B4MJ += (jc9 ^ w1Oh5).toString(16);
B4MJ = B4MJ.slice(-6);
return B4MJ;
}
'''
c3vk = execjs.compile(js_text).call('get_c3vk', args1)
print('c3vk: ', c3vk)
return c3vk
def run(self):
res = self.session.get(self.url_first)
print(res.text)
cookies = requests.utils.dict_from_cookiejar(self.session.cookies)
cookies['C3VK'] = self.get_cookie_c3vk(res)
self.session.cookies.update(cookies)
self.session.headers.update(self.headers_data)
for page in range(1, 5):
self.payload['page'] = page
response = self.session.post(self.url_data, data=self.payload)
# print(response.text)
if isinstance(response.content, bytes):
encoding = cchardet.detect(response.content)['encoding']
html = response.content.decode(encoding, 'ignore')
print(html)
if __name__ == '__main__':
tax = Chinatax()
tax.run()
下一篇:房天下登录密码加密js分析
相关文章
文章评论
暂无评论添加评论
点击排行
本栏推荐
标签云
热评文章
- django使用qq邮箱发送邮件
- mysql8设置数据库远程连接
- pip修改下载源为国内源
- win10看不到win7共享的文件夹的解决方法
- SQLyog连接 Mysql 8.0.11 报error no.1251- Client does not support authentic...
- 使用Oracel Net Nanager配置Oracle数据库远程访问
- 将anaconda的下载源切换为国内的源
- Python+selenium+firefox设置代理IP
- selenium+firefox+js实现动态设置firefox浏览器代理IP
- scrapy文件下载(高新技术企业认定网)
- Python调用JS代码
- Chrome浏览器的overrides的使用
站点信息
- 建站时间:2021-01-01
- 网站程序:Django 3.1.2
- 文章统计:54篇
- 文章评论:43条
- 统计数据: